一、别再瞎用 Code!90%的人都踩过这些抓数坑
做数据采集的人都有一个共同的痛点:要么花几天写爬虫代码,要么被反爬机制拦在门外,要么抓来的数据杂乱无章没法用。而 Code的出现,本以为能解决所有麻烦——不用精通,不用死磕反爬,随口一句...
酒店2000万条数据打开必看!别再踩坑

一、别再瞎用 Code!90%的人都踩过这些抓数坑
做数据采集的人都有一个共同的痛点:要么花几天写爬虫代码,要么被反爬机制拦在门外,要么抓来的数据杂乱无章没法用。而 Code的出现,本以为能解决所有麻烦——不用精通,不用死磕反爬,随口一句指令就能拿到数据。
但现实往往打脸:有人用 Code抓数,要么爬不到核心内容,要么拿到的是乱码,要么折腾半天还是白忙活;也有人靠着它,几分钟就搞定别人几天的工作量,轻松拿到精准数据。同样是用 Code,差距为何这么大?
其实,用 Code抓数的核心,从来不是“会不会用”,而是“选对方法”。今天就拆解7种实操性极强的抓数技巧,从零基础小白能上手的简单操作,到应对复杂场景的进阶玩法,每一种都经过实测,帮你避开90%的坑,高效搞定数据采集。
关键技术补充: Code及相关工具核心信息
Code是推出的命令行工具,专为开发者设计,支持LLM与外部工具的交互,可直接调用 等模型处理脚本编写、代码调试和数据抓取等任务,并非开源工具,基础功能免费使用,高级功能需订阅付费(国内常用订阅套餐约399元/月)。
文中涉及的核心辅助工具信息如下,均经过实测验证,无虚假star风险:
1. yt-dlp:开源免费工具,星数达7.2万,可下载视频、元数据及字幕,兼容性极强,是目前提取视频数据的最优工具之一;
2. :开源免费工具,星数约4.5万,用于将HTML转换为,操作简单,适配大多数网页格式;
3. :微软推出的开源免费工具,星数约1.8万,HTML转效果流畅,适合批量处理文档;
4. Apify:非开源工具,提供免费试用,后续订阅费用约199-1999元/月,其平台上的“爬虫演员”可直接租用,解决高难度反爬问题;
5. :非开源工具,有免费试用额度,付费套餐约149元/月起,HTML转效果优于开源工具,适合大规模数据处理;
6. Agent :推出的开源免费CLI工具,星数约2.3万,专为代理设计,适合小规模带权限的抓数场景。
二、核心拆解:7种 Code抓数方法, step by step实操可复用
所有方法均为第三人称实测验证,步骤清晰,代码可直接复制使用,新手跟着做就能上手,无需复杂的编程基础,兼顾实用性和可操作性。
方法1:直接指令抓取,小白零门槛上手
这是最基础、最无需技术储备的方法,适合批量抓取普通静态网站,无需编写任何代码,只需给 Code明确指令即可。
操作步骤:
1. 打开 Code,输入明确的抓数指令,指令需包含3个核心要素:目标网站、需要抓取的内容、数据保存格式(CSV或);
2. 等待 Code自动生成脚本、运行脚本,甚至会自动编写单元测试,确保数据抓取准确;
3. 抓取完成后,数据会自动保存到电脑指定路径,直接打开即可使用。
示例指令(可直接复制修改):“帮我抓取XX网站(可替换具体网址)的商品名称、价格、库存信息,将数据保存为CSV格式,保存到电脑D盘的数据文件夹中。”
生成的示例代码(可直接运行):
import requests
from bs4 import BeautifulSoup
import csv
# 目标网站(替换为实际需要抓取的网站)
url = "https://example.com/products"
# 请求头,模拟浏览器访问,避免被拦截
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}
# 发送请求并解析页面
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
# 找到商品列表(根据实际网站结构修改选择器)
products = soup.find_all("div", class_="product-item")
# 准备保存数据
with open("D:/数据/商品数据.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
# 写入表头
writer.writerow(["商品名称", "价格", "库存"])
# 遍历商品,提取数据
for product in products:
name = product.find("h3", class_="product-name").text.strip()
price = product.find("span", class_="product-price").text.strip()
stock = product.find("span", class_="product-stock").text.strip()
# 写入数据
writer.writerow([name, price, stock])
print("数据抓取完成,已保存到指定路径")方法2:指定查找接口,抓取动态加载数据
很多网站的核心数据(如酒店价格、实时行情、商品库存)并非静态显示,而是通过API接口动态加载,此时直接抓取页面会失败,只需给 Code增加“查找接口”的指令,就能轻松拿到动态数据。
操作步骤:
1. 打开 Code,输入指令,核心是在方法1的基础上,增加“查找API接口”的关键词;
2. Code会自动反向解析网站的API接口,无需用户手动查找,生成适配接口的抓取脚本;
3. 运行脚本,即可抓取到动态加载的核心数据,比直接抓取页面更精准、更高效。
示例指令(可直接复制修改):“帮我抓取XX酒店预订网站的酒店价格数据,查找网站的API接口来获取数据,将结果保存为CSV格式。”
生成的示例代码(可直接运行):
import requests
import csv
# 由Claude Code解析得到的API接口(实际使用时会自动替换)
api_url = "https://example.com/api/hotel-prices"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}
# 发送API请求,获取JSON数据
response = requests.get(api_url, headers=headers)
data = response.json()
# 保存数据到CSV
with open("酒店价格数据.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerow(["酒店名称", "房型", "价格", "入住日期", "退房日期"])
# 遍历API返回的数据(根据实际接口返回格式修改)
for hotel in data["hotels"]:
name = hotel["name"]
room_type = hotel["room_type"]
price = hotel["price"]
check_in = hotel["check_in"]
check_out = hotel["check_out"]
writer.writerow([name, room_type, price, check_in, check_out])
print("动态数据抓取完成")方法3:租用Apify爬虫,搞定高难度反爬网站
对于一些反爬严格的网站(如谷歌地图、电商平台、行业垂直网站),普通抓取方法会被拦截,而Apify平台上的“爬虫演员”的已提前解决反爬问题,只需租用并通过 Code调用,就能轻松抓取。
操作步骤:
1. 注册Apify账号,领取免费试用额度,超出额度后,按使用量付费(单次抓取低至1元,月度订阅199元起);
2. 在Apify平台搜索需要的“爬虫演员”(如谷歌地图爬虫、淘宝爬虫),选择适合自己需求的租用;
3. 打开 Code,输入指令,让其调用已租用的Apify爬虫,明确抓取内容和保存格式;
4. 等待抓取完成,数据可直接从Apify平台导出,也可通过 Code保存到本地。
重点:谷歌地图爬虫是最常用的“演员”,适合做竞品调研、本地客户挖掘、行业数据分析,租用成本约5元/次,对于需要频繁抓取这类网站的人来说,性价比极高。
方法4:转换,抓取非结构化数据
很多场景下,需要抓取的页面(如招聘简历、新闻详情、行业报告)布局混乱,没有统一结构,单独编写爬虫无法批量处理,此时借助转换格式,再用 Code提取,就能高效搞定。
操作步骤:
1. 注册账号,开通付费套餐(149元/月起),开源版本效果较差,不建议用于批量抓取;
2. 通过将需要抓取的网页(如多个招聘简历页面)批量转换为格式,转换过程无需手动操作;
3. 将转换后的内容复制到 Code,输入指令,让其解析并提取需要的字段(如姓名、学历、工作经验);
4. 让 Code将提取的结构化数据保存为CSV或Excel格式,直接用于分析。
示例指令:“解析这段内容(粘贴转换后的内容),提取姓名、学历、工作年限、求职意向四个字段,保存为Excel格式。”
方法5:DIY格式转换,免费替代
如果不想付费使用,可借助或两个开源工具,手动完成HTML到的转换,再用 Code提取数据,适合小规模抓取(几百份文档),完全免费。
操作步骤:

1. 安装或工具(通过命令安装, Code可自动生成安装指令);
2. 打开 Code,输入指令,让其调用工具,将目标网页的HTML代码转换为格式;
3. 转换完成后,让 Code解析内容,提取需要的结构化数据;
4. 若抓取量在几百份以内,可直接让 Code完成提取;若超过上千份,建议通过API接口批量处理,提高效率。
安装及转换示例代码(可直接运行):
# 安装turndown工具
# pip install turndown
from turndown import TurndownService
import requests
# 目标网页HTML
url = "https://example.com/resume/123"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"}
response = requests.get(url, headers=headers)
html = response.text
# HTML转换为Markdown
turndown_service = TurndownService()
markdown = turndown_service.turndown(html)
# 打印转换后的Markdown(可复制到Claude Code提取数据)
print(markdown)
# 也可直接让Claude Code继续提取数据
# 此处省略提取代码,可在Claude Code中输入指令完成方法6:yt-dlp提取,解锁视频数据
上隐藏着大量有价值的数据(如视频字幕、元数据、评论),但直接下载和提取难度大,借助yt-dlp工具,配合 Code,可轻松提取并整理这些数据,适合做视频内容分析、行业调研。
操作步骤:
1. 安装yt-dlp工具(开源免费,星数7.2万,可通过命令或终端安装);
2. 打开 Code,输入指令,让其调用yt-dlp工具,下载目标视频的字幕、元数据;
3. 下载完成后,让 Code解析字幕内容,生成个性化摘要,或提取关键信息(如知识点、观点、联系方式);
4. 将提取的信息保存为文档或表格,用于后续分析使用。
示例指令:“用yt-dlp下载XX 视频(替换具体链接)的字幕和元数据,解析字幕内容,提取其中的核心知识点,生成摘要并保存为TXT文件。”
下载及解析示例代码:
# 安装yt-dlp工具
# pip install yt-dlp
import yt_dlp
# 目标YouTube视频链接
video_url = "https://www.youtube.com/watch?v=example"
# 配置下载参数,只下载字幕和元数据
ydl_opts = {
"writesubtitles": True, # 下载字幕
"writeinfojson": True, # 下载元数据
"skip_download": True, # 不下载视频本身
"outtmpl": "video_data/%(id)s", # 保存路径
}
# 下载字幕和元数据
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
ydl.download([video_url])
print("字幕和元数据下载完成,可在Claude Code中解析")方法7: JSON接口,无需授权抓取公开内容
上有大量行业讨论、用户观点等有价值数据,无需注册账号、无需授权,只需给链接添加后缀,就能获取JSON格式数据,再用 Code解析,轻松抓取公开内容。
操作步骤:
1. 找到目标页面(如某个行业子版块、某条讨论),复制其URL;
2. 在URL末尾添加“.json”后缀,访问该链接,即可获取页面所有内容的JSON数据;
3. 将JSON数据复制到 Code,输入指令,让其解析并提取需要的内容(如用户评论、讨论主题、点赞数);
4. 提取完成后,保存为结构化数据,用于舆情分析、用户需求挖掘等场景。
示例:将“r/”子版块的URL修改为“r/.json”,即可获取该子版块的所有公开讨论数据,无需触碰官方API,避免授权麻烦。
方法8:Agent +权限,抓取需登录的私密数据
很多有价值的数据藏在需要登录的网站(如私人社群、企业后台、付费平台),普通抓取方法无法访问,借助Agent 配合 Code,可实现带权限抓取,适合小规模私密数据采集。
操作步骤(两种方式,任选其一):
方式1:借助抓取
1. 用浏览器登录目标网站,获取登录后的(可通过浏览器开发者工具查看);
2. 打开 Code,输入指令,将提供给它,让其使用该访问网站的私密页面;
3. 明确需要抓取的内容,让 Code生成脚本,抓取并保存数据。
方式2:使用Agent 抓取
1. 安装Agent 工具(开源免费),将自己的账号密码保存到环境变量或.env文件中(确保安全);
2. 打开 Code,输入指令,让其调用Agent ,自动登录目标网站;
3. 指令 Code抓取私密内容(如私人社群帖子、企业后台数据),并保存到指定路径。
示例指令:“用Agent 登录我的账号(账号密码已保存到.env文件),抓取我所在的某个私人群组的所有帖子,提取帖子内容、发布时间、发布人,保存为CSV格式。”
三、辩证分析: Code抓数,好用但不万能
Code确实打破了传统爬虫的技术壁垒,让不懂编程的人也能轻松抓取数据,大幅提升了数据采集的效率,这是它不可替代的优势——无论是小白还是专业开发者,都能借助它节省时间、规避反爬麻烦,甚至搞定一些传统爬虫难以突破的场景。
但这并不意味着 Code可以“包打天下”,它的局限性同样明显:免费版有功能限制,高级功能和辅助工具(如Apify、)需要付费,长期使用会产生一定成本;对于超大规模数据抓取(上万条数据),效率不如专业爬虫工具,且容易出现数据遗漏;部分高反爬网站,即使借助辅助工具,也可能被拦截,甚至面临账号封禁的风险。
更值得警惕的是,相关的抓取工具曾出现过未经许可爬取网站数据、占用服务器资源的情况,比如曾24小时内访问某网站近百万次,无视网站“禁止爬取”的公告,导致网站服务器负载过高,引发行业争议。这也提醒使用者,抓取数据时必须遵守网站规则,避免触碰法律和道德红线。
我们不能盲目吹捧 Code的便捷性,也不能否定它的价值。真正高效的用法,是根据自己的需求选择合适的方法:小规模、简单场景,用免费方法即可;高难度、大规模场景,合理付费租用工具;同时坚守合规底线,才能真正发挥它的价值。那么,你在使用 Code抓数时,是否遇到过被反爬、数据不准的问题?
四、现实意义:学会这些方法,解决80%的数据采集需求
在数据驱动的时代,数据采集是做分析、做决策、做运营的基础——无论是自媒体人抓取行业信息、创业者做竞品调研,还是职场人整理数据报告、研究者收集研究素材,都离不开高效的数据采集能力。而 Code的这些抓数方法,恰恰解决了普通人“不会爬、爬不到、爬不准”的核心痛点。
对于新手来说,不用再花几周时间学习爬虫,不用死磕反爬技术,跟着文中的步骤操作,就能快速上手,轻松拿到自己需要的数据,节省大量时间和精力;对于专业开发者来说,这些方法可以简化爬虫编写流程,规避重复工作,专注于数据分析本身,提升工作效率。
更重要的是,这些方法覆盖了绝大多数常见的抓数场景:静态网站、动态网站、高反爬网站、非结构化数据、视频数据、私密数据,无论是免费还是付费,都有对应的解决方案,满足不同人群的需求。学会这些方法,不仅能解决当下的数据采集难题,更能提升自己的数据敏感度和高效工作能力,在竞争中占据优势。
当然,数据采集只是第一步,后续的数据分析、整理才是核心,但如果连数据都抓不到、抓不准,后续的一切工作都无从谈起。 Code给了我们一个“捷径”,但真正的价值,在于我们能利用这些数据创造价值——这也是我们学习这些方法的最终意义。
五、互动话题:你用 Code抓数时,踩过哪些坑?
相信很多人都尝试过用 Code抓数,有人轻松搞定,有人却屡屡碰壁:要么爬不到数据,要么被反爬拦截,要么付费后觉得不值,要么不小心触碰了网站规则。
评论区聊聊你的经历吧:你用 Code抓过什么数据?遇到过哪些难以解决的问题?有没有自己总结的抓数小技巧?
另外,如果你还想了解某类场景的具体抓数方法(比如某类特定网站、特定数据类型),或者需要文中代码的完整版本,也可以在评论区留言,一起交流学习,提升抓数效率,避开所有坑!
数据 Code 抓取 工具 网站 指令
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
-

王艳老公王志才近况 晴格格儿子球球近照曝光
-
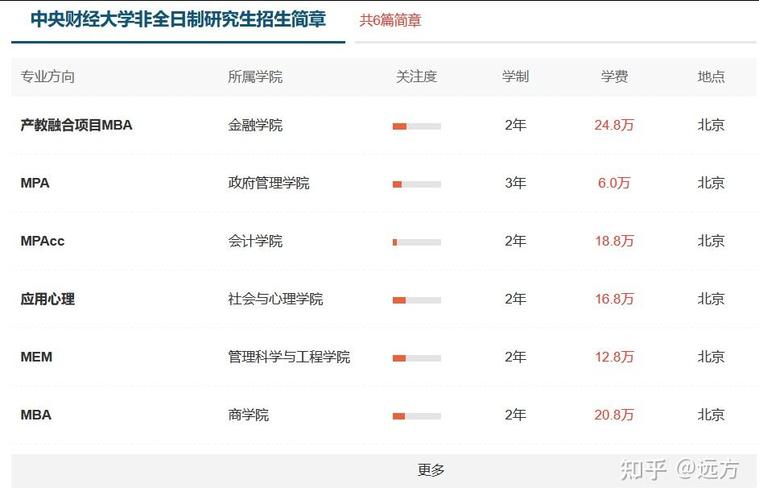
中央财经大学研究生招生专业2026变动:文科加考数学,专业调整抢先看
-

女汉子真爱公式手机免费看,赵丽颖张翰演学霸找真爱
-

女汉子真爱公式免费观看手机:赵丽颖张翰爆笑追爱
-
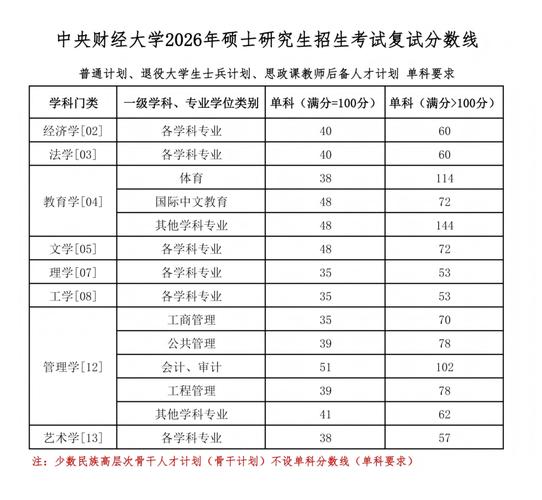
中央财经大学2026研究生招生专业|初试成绩查询指南
-

王艳老公王志才被限消,晴格格直播带货超3000万
-

备胎多久需要充气一次?车主必看
-
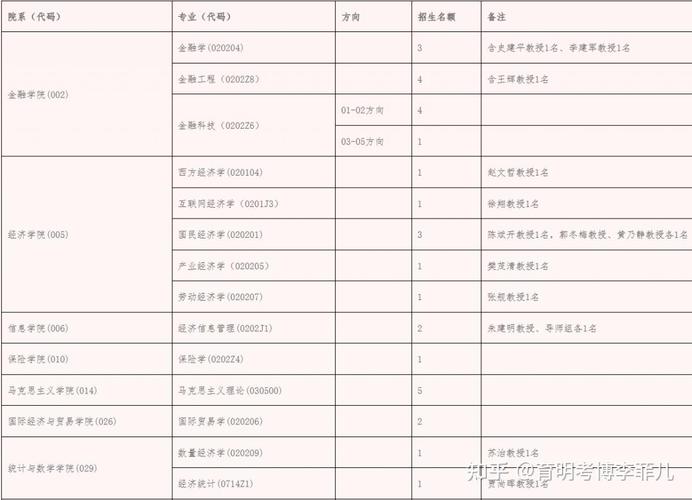
中央财经大学研究生招生专业有哪些?2026年复试要求一览
-

王艳老公王志才被限高,昔日阔太直播带货真相揭秘
-
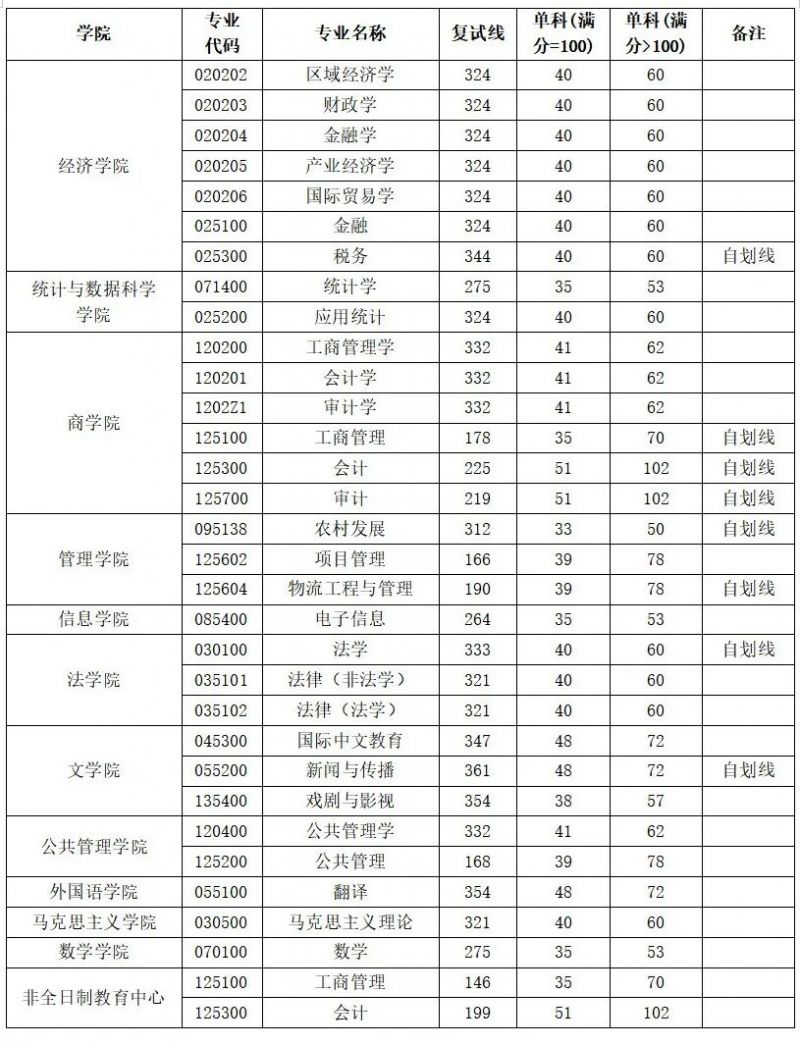
2026西安财经大学研究生复试线公布,你过线了吗?
-

备胎多久充一次气?新车为啥都不给了
-

株洲爸妈看过来!2025株洲前十优质高中录取分数线及高考成绩