爬虫教程系列、从0到1学习爬虫
爬虫教程系列、从0到1学习爬虫爬虫教程系列、从0到1学习爬虫,包括浏览器抓包,手机APP抓包,如 、,各种爬虫涉及的模块的使用,如:、、、、等,以及IP代理,验证码识别,Mysql,数据库的使用,多线程多进...
Python爬虫入门实战:用BeautifulSoup轻松下载电子书
爬虫教程系列、从0到1学习爬虫
爬虫教程系列、从0到1学习爬虫爬虫教程系列、从0到1学习爬虫,包括浏览器抓包,手机APP抓包,如 、,各种爬虫涉及的模块的使用,如:、、、、等,以及IP代理,验证码识别,Mysql,数据库的使用,多线程多进程爬虫的使用,css 爬虫加密逆向破解,JS爬虫逆向,分布式爬虫,爬虫项目实战实例等
立即下载
爬虫实战案例教程.pdf
以一个电子书的网站为例来实现爬虫获取电子书资源。爬取整站的电子书资源,按目录保存到本地,并形成索引文件方便查找。爬取的目标网站:苦瓜书盘步骤:爬取->分析、解析->保存对于一个不需要登录验证的资源分享类的网站,爬取最大的工作量应该是在对目标页面的分析、解析、识别,这里用的到是的库。一、获取目录二、获取书籍列表页三、获取书籍详情页四、分析书籍详情页的资源地址五、下载并保存
立即下载
爬虫包简介与安装(一)
主要为大家详细介绍了爬虫包的简介与安装,具有一定的参考价值,感兴趣的朋友可以参考一下
立即下载
爬虫实例——基于与.
爬虫实例——基于与.,思路是打开目标链接,并爬取通过一定区域中的img标签中的src进行保存。
立即下载
推荐了许多爬虫实例,也推荐了用于练习的网站
推荐了许多爬虫实例,也推荐了用于练习的网站
立即下载
爬虫库的介绍与简单使用实例
一、介绍库是灵活又方便的网页解析库,处理高效,支持多种解析器。利用它不用编写正则表达式即可方便地实现网页信息的提取。常用解析库解析器使用方法优势劣势标准库(, “html.”)的内置标准库、执行速度适中 、文档容错能力强 2.7.3 or 3.2.2)前的版本中文容错能力差lxml HTML 解析器(, “lxml”)速度快、文档容错能力强需要安装C语言库lxml XML 解析器Bea
立即下载
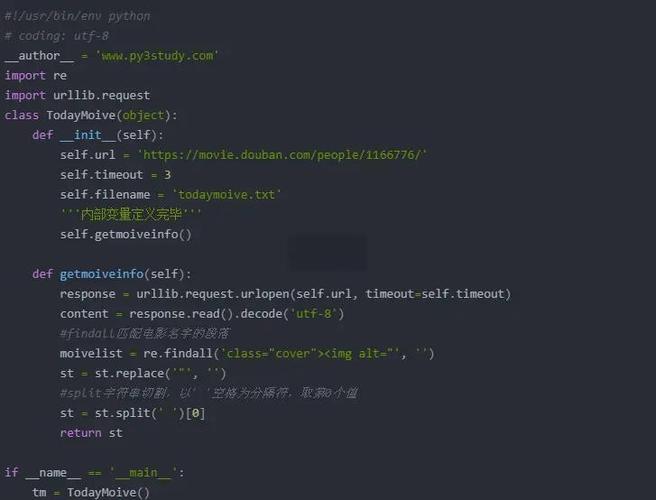
爬虫包 递归抓取实例详解
爬虫包 递归抓取实例详解概要:爬虫的主要目的就是为了沿着网络抓取需要的内容。它们的本质是一种递归的过程。它们首先需要获得网页的内容,然后分析页面内容并找到另一个URL,然后获得这个URL的页面内容,不断重复这一个过程。让我们以维基百科为一个例子。 我们想要将维基百科中凯文·贝肯词条里所有指向别的词条的链接提取出来。# -*- : utf-8 -*-# @: # @Date: 2016-12-25 10:35:00# @Last by: # @Last M
立即下载
爬虫要点和难点实例代码解析
爬虫要点和难点实例代码解析
立即下载
爬虫学习实例
爬虫学习实例
立即下载
作品提交爬虫源码实例
京东评论爬虫
立即下载
爬虫包实例(三)
主要为大家详细介绍了爬虫包实例,具有一定的参考价值,感兴趣的朋友可以参考一下
立即下载
爬虫实例 +解析 HTML 页面一个简单的网页上抓取标题和链接
爬虫实例 +解析 HTML 页面一个简单的网页上抓取标题和链接 爬虫是一种自动化程序,用于从网站上抓取数据。这里我将提供一个简单的 爬虫实例,使用 库来发送 HTTP 请求,以及 库来解析 HTML 页面。这个实例将从一个简单的网页上抓取标题和链接。首先,你需要安装必要的库。如果你还没有安装 和 ,可以通过 pip 安装:pip
立即下载
爬虫 实例 解析 下载 立即 一个
热门文章
-
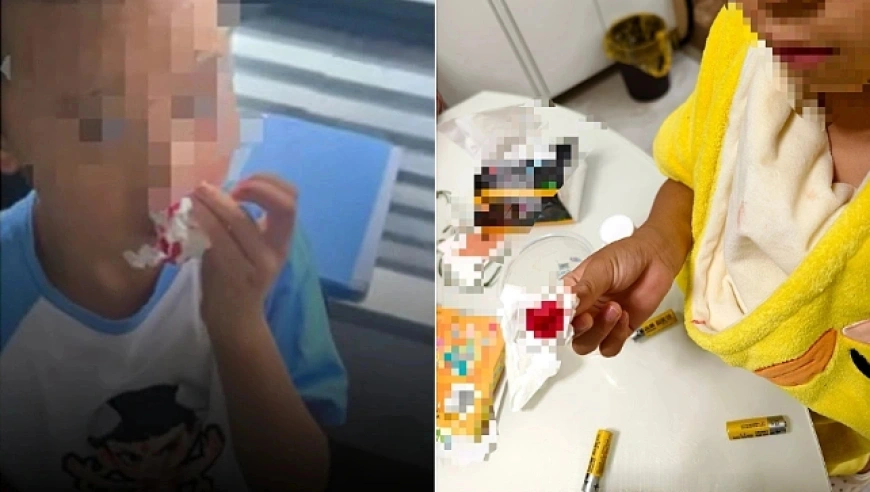
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-
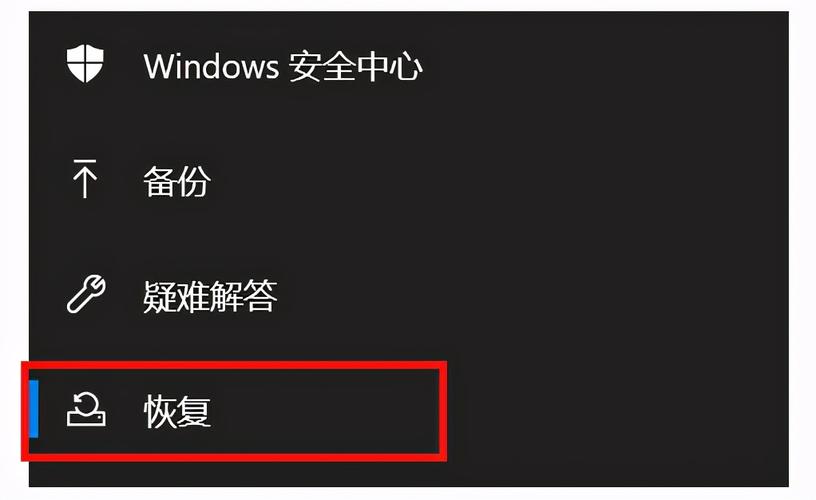
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
-

王艳老公王志才近况 晴格格儿子球球近照曝光
-
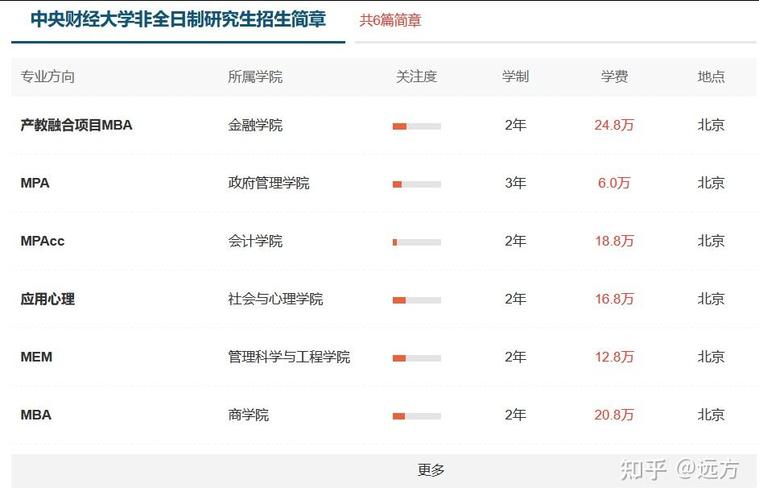
中央财经大学研究生招生专业2026变动:文科加考数学,专业调整抢先看
-

女汉子真爱公式手机免费看,赵丽颖张翰演学霸找真爱
-

女汉子真爱公式免费观看手机:赵丽颖张翰爆笑追爱
-
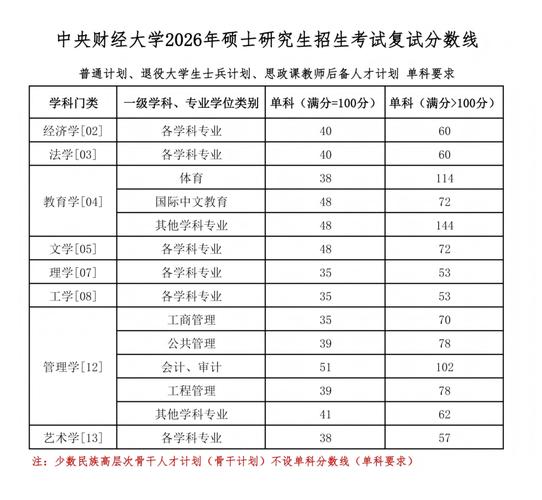
中央财经大学2026研究生招生专业|初试成绩查询指南
-

王艳老公王志才被限消,晴格格直播带货超3000万
-

备胎多久需要充气一次?车主必看
-
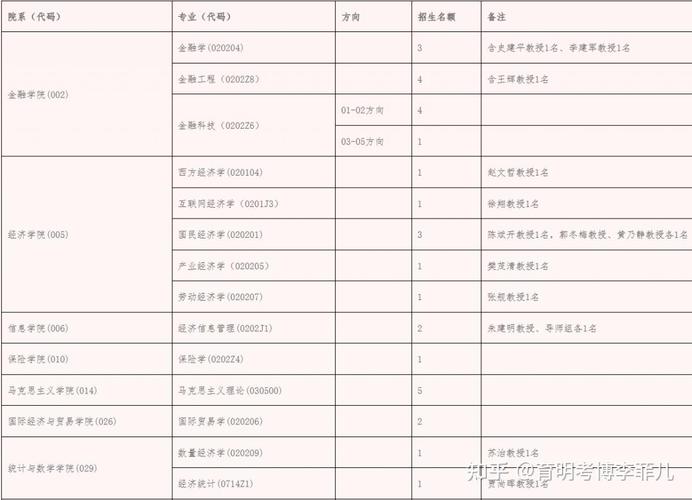
中央财经大学研究生招生专业有哪些?2026年复试要求一览
-

王艳老公王志才被限高,昔日阔太直播带货真相揭秘
-
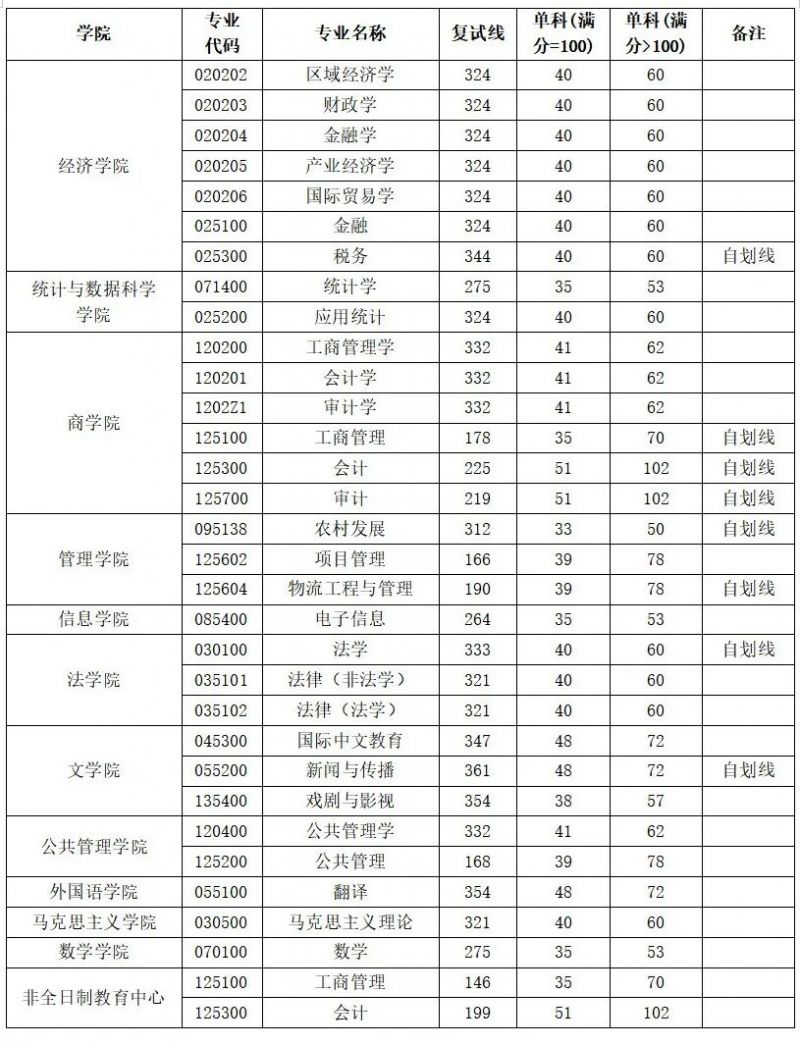
2026西安财经大学研究生复试线公布,你过线了吗?
-

备胎多久充一次气?新车为啥都不给了
-

株洲爸妈看过来!2025株洲前十优质高中录取分数线及高考成绩