C10K和C10M
计算机领域的很多技术都是需求推动的,上世纪90年代,由于互联网的飞速发展,网络服务器无法支撑快速增长的用户规模。1999年,Dan Kegel提出了著名的C10问题:一台服务器上同时处理10000个客户网络连接。1000...
C10K问题的由来及现状:计算机领域技术受需求推动?
C10K和C10M
计算机领域的很多技术都是需求推动的,上世纪90年代,由于互联网的飞速发展,网络服务器无法支撑快速增长的用户规模。1999年,Dan Kegel提出了著名的C10问题:一台服务器上同时处理10000个客户网络连接。10000个网络连接并不会发送请求到服务器,有些连接并不活跃,同一时刻,只有极少的部分连接发送请求。不同的服务类型,每个连接发送请求的频率也不相同,游戏服务器的连接会频繁的发送请求,而Web服务器的连接发送请求的频率就低很多。无论如何,根据经验法则,对于特定的服务类型,连接越多,同一时刻发送请求的连接也越多。
时至今日,C10K问题当然早已解决,不仅如此,一台机器能支撑的连接越来越多,后来提出了C10M问题,在一台机器上支撑1000万的连接,2015年,在单机承载12M的连接,解决了C10M问题。
本文先回顾C10问题的解决方案,再探讨如何构建支撑C10M的应用程序,聊聊其中涉及的各种技术。
C10K问题的解决
时间退回到1999年,当时要实现一个网络服务器,大概有这样几种模式
简单进程/线程模型
这是一种非常简单的模式,服务器启动后监听端口,阻塞在上,当新网络连接建立后,返回新连接,服务器启动一个新的进程/线程专门负责这个连接。从性能和伸缩性来说,这种模式是非常糟糕的,原因在于
有意思的是,这种模式虽然性能极差,但却依然是我们今天最常见到的模式,很多Web程序都是这样的方式在运行。
/poll
另外一种方式是使用/poll,在一个线程内处理多个客户连接。和poll能够监控多个文件描述符,当某个文件描述符就绪,/soll从阻塞状态返回,通知应用程序可以处理用户连接了。使用这种方式,我们只需要一个线程就可以处理大量的连接,避免了多进程/线程的开销。之所以把和poll放在一起说,原因在于两者非常相似,性能上基本没有区别,唯一的区别在于poll突破了 1024个文件描述符的限制,然而当文件描述符数量增加时,poll性能急剧下降,因此所谓突破1024个文件描述符实际上毫无意义。/poll并不完美,依然存在很多问题:
每次调用/poll,都要把文件描述符的集合从用户地址空间复制到内核地址空间/poll返回后,调用方必须遍历所有的文件描述符,逐一判断文件描述符是否可读/可写。
这两个限制让/poll完全失去了伸缩性。连接数越多,文件描述符就越多,文件描述符越多,每次调用/poll所带来的用户空间到内核空间的复制开销越大。最严重的是当报文达到,/poll返回之后,必须遍历所有的文件描述符。假设现在有1万个连接,其中只一个连接发送了请求,但是/poll就要把1万个连接全部检查一遍。
epoll
4.1引入了,此时是2000年7月,而在Linux上,还要等待2年后的2002年才开始引入的类似实现: epoll。epoll最初于 2.5.44进入Linux ,此时已经是2002年,距离C10K问题提出已经过了3年。
epoll是如何提供一个高性能可伸缩的IO多路复用机制呢?首先,epoll引入了epoll 这个概念,epoll 在内核中关联了一组要监听的文件描述符配置: list,这样的好处在于,每次要增加一个要监听的文件描述符,不需要把所有的文件描述符都配置一次,然后从用户地址空间复制到内核地址空间,只需要把单个文件描述符复制到内核地址空间,复制开销从O(n)降到了O(1)。
注册完文件描述符后,调用开始等待文件描述符事件。可以只返回已经ready的文件描述符,因此,在返回之后,程序只需要处理真正需要处理的文件描述符,而不用把所有的文件描述符全部遍历一遍。假设在全部N个文件描述符中,只有一个文件描述符Ready,/poll要执行N次循环,epoll只需要一次。
epoll出现之后,Linux上才真正有了一个可伸缩的IO多路复用机制。基于epoll,能够支撑的网络连接数取决于硬件资源的配置,而不再受限于内核的实现机制。CPU越强,内存越大,能支撑的连接数越多。
编程模型
和
不同的操作系统上提供了不同的IO多路复用实现,Linux上有epoll,有,有IOCP。对于需要跨平台的程序,必然需要一个抽象层,提供一个统一的IO多路复用接口,屏蔽各个系统接口的差异性。
是实现这个目标的一次尝试,最早出现在 C. 的论文"The An - for Event- Port and "中。从论文的名字可以看出,是poll这种编程模式的一个面向对象包装。考虑到论文的时间,当时正是面向对象概念正火热的时候,什么东西都要蹭蹭面向对象的热度。论文中,DC 描述了为什么要做这样的一个,给出了下面几个原因
操作系统提供的接口太复杂,容易出错。和poll都是通用接口,因为通用,增加了学习和正确使用的复杂度。接口抽象层次太低,涉及太多底层的细节。不能跨平台移植。难以扩展。
实际上除了第三条跨平台,其他几个理由实在难以站得住脚。/poll这类接口复杂吗,使用起来容易出错吗,写出来的程序难以扩展吗?不过不这么说怎么体现的价值呢。正如论文名称所说的,本质是对操作系统IO多路复用机制的一个面向对象包装,为了证明的价值,DC 还用C++面向对象的特性实现了一个编程框架:ACE,实际上使用ACE比直接使用poll或者epoll复杂多了。
后来DC 写了一本书《面向模式的软件架构》,再次提到了,并重新命名为 ,现在网络上能找到的资料,基本上都是基于 ,而不是早期的面向- 。
《面向模式的软件》架构中还提到了另外一种叫做的模式,和非常类似,针对同步IO,则针对异步IO。
,和纤程
看上去并不复杂,但是想编写一个完整的应用程序时候就会发现其实没那么简单。为了避免主逻辑阻塞,所有可能会导致阻塞的操作必须注册到epoll上,带来的问题就是处理逻辑的支离破碎,大量使用,产生的代码复杂难懂。如果应用程序中还有非网络IO的阻塞操作,问题更严重,比如在程序中读写文件。Linux中文件系统操作都是阻塞的,虽然也有Linux AIO,但是一直不够成熟,难堪大用。很多软件采用线程池来解决这个问题,不能通过epoll解决的阻塞操作,扔到一个线程池执行。这又产生了多线程内存开销和上下文切换的问题。
机制是对的简单优化,本质上还是,但是提供了一致的接口,代码相对来说简单一些,不过在实际使用中还是比较复杂的。是一个非常彻底的风格的框架,从它的代码可以看到这种编程风格真的非常复杂,阻塞式编程中一个函数几行代码就能搞定的事情,在里需要上百行代码,几十个 (在里叫做)。
纤程是一种用户态调度的线程,比如Go语言中的,有些人可能会把这种机制成为,不过我认为和纤程还是有很大区别的,是泛化的子进程,具有多个进入和退出点,用来一些一些相互协作的程序,典型的例子就是中的。纤程则是一种运行和调度机制。
纤程真正做到了高性能和易用,在Go语言中,使用实现的高性能服务器是一件轻松愉快的事情,完全不用考虑线程数、epoll、回调之类的复杂操作,和编写阻塞式程序完全一样。
网络优化
网络子系统是Linux内核中一个非常庞大的组件,提供了各种通用的网络能力。通用通常意味在在某些场景下并不是最佳选择。实际上业界的共识是Linux内核网络不支持超大并发的网络能力。根据我过去的经验,Linux最大只能处理1MPPS,而现在的网卡通常可以处理。随着更高性能的,网卡出现,Linux内核网络能力越发捉襟见肘。
为什么Linux不能充分发挥网卡的处理能力?原因在于:
Linux高性能网络一个方向就是绕过内核的网络栈( ),业界有不少尝试
技术最大的问题在于不支持POSIX接口,用户没办法不修改代码直接移植到一种 技术上。对于大多数程序来说,还要要运行在标准的内核网络栈上,通过调整内核参数提升网络性能。
网卡多队列
报文到达网卡之后,在一个CPU上触发中断,CPU执行网卡驱动程序从网卡硬件缓冲区读取报文内容,解析后放到CPU接收队列上。这里所有的操作都在一个特定的CPU上完成,高性能场景下,单个CPU处理不了所有的报文。对于支持多队列的网卡,报文可以分散到多个队列上,每个队列对应一个CPU处理,解决了单个CPU处理瓶颈。
为了充分发挥多队列网卡的价值,我们还得做一些额外的设置:把每个队列的中断号绑定到特定CPU上。这样做的目的,一方面确保网卡中断的负载能分配到不同的CPU上,另外一方面可以将负责网卡中断的CPU和负责应用程序的CPU区分开,避免相互干扰。

在Linux中,/sys/class/net/${}//下保存了每个队列的中断号,有了中断号之后,我们就可以设置中断和CPU的对应关系了。网上有很多文章可以参考。
网卡
回忆下TCP数据的发送过程:应用程序将数据写到套接字缓冲区,内核将缓冲区数据切分成不大于MSS的片段,附加上TCP 和IP ,计算,然后将数据推到网卡发送队列。这个过程中需要CPU全程参与, 随着网卡的速度越来越快,CPU逐渐成为瓶颈,CPU处理数据的速度已经赶不上网卡发送数据的速度。经验法则,发送或者接收1bit/s TCP数据,需要1Hz的CPU,1Gbps需要1GHz的CPU,需要10GHz的CPU,已经远超单核CPU的能力,即使能完全使用多核,假设单个CPU Core是2.5GHz,依然需要4个CPU Core。
为了优化性能,现代网卡都在硬件层面集成了TCP分段、添加IP 、计算等功能,这些操作不再需要CPU参与。这个功能叫做tcp ,简称tso。使用 -k 可以检查网卡是否开启了tso
除了tso,还有其他几种,比如支持udp分片的ufo,不依赖驱动的gso,优化接收链路的lro
充分利用多核
随着摩尔定律失效,CPU已经从追求高主频转向追求更多的核数,现在的服务器大都是96核甚至更高。构建一个支撑C10M的应用程序,必须充分利用所有的CPU,最重要的是程序要具备水平伸缩的能力:随着CPU数量的增多程序能够支撑更多的连接。
很多人都有一个误解,认为程序里使用了多线程就能利用多核,考虑下程序,你可以创建多个线程,但是由于GIL的存在,程序最多只能使用单个CPU。实际上多线程和并行本身就是不同的概念,多线程表示程序内部多个任务并发执行,每个线程内的任务可以完全不一样,线程数和CPU核数没有直接关系,单核机器上可以跑几百个线程。并行则是为了充分利用计算资源,将一个大的任务拆解成小规模的任务,分配到每个CPU上运行。并行可以 通过多线程实现,系统上有几个CPU就启动几个线程,每个线程完成一部分任务。
并行编程的难点在于如何正确处理共享资源。并发访问共享资源,最简单的方式就加锁,然而使用锁又带来性能问题,获取锁和释放锁本身有性能开销,锁保护的临界区代码不能只能顺序执行,就像的GIL,没能充分利用CPU。
Local和Per-CPU变量
这两种方式的思路是一样的,都是创建变量的多个副本,使用变量时只访问本地副本,因此不需要任何同步。现代编程语言基本上都支持 Local,使用起来也很简单,C/C++里也可以使用标记声明变量。
Per-CPU则依赖操作系统,当我们提到Per-CPU的时候,通常是指Linux的Per-CPU机制。Linux内核代码中大量使用Per-CPU变量,但应用代码中并不常见,如果应用程序中工作线程数等于CPU数量,且每个线程Pin到一个CPU上,此时才可以使用。
原子变量
如果共享资源是int之类的简单类型,访问模式也比较简单,此时可以使用原子变量。相比使用锁,原子变量性能更好。在竞争不激烈的情况下,原子变量的操作性能基本上和加锁的性能一致,但是在并发比较激烈的时候,等待锁的线程要进入等待队列等待重新调度,这里的挂起和重新调度过程需要上下文切换,浪费了更多的时间。
大部分编程语言都提供了基本变量对应的原子类型,一般提供set, get, 等操作。
lock-free
lock-free这个概念来自
An is non‐ if or of any cause or of ; an is lock‐free if, at each step, some can make .
non-算法任何线程失败或者挂起,不会导致其他线程失败或者挂起,lock-free则进一步保证线程间无依赖。这个表述比较抽象,具体来说,non-要求不存在互斥,存在互斥的情况下,线程必须先获取锁再进入临界区,如果当前持有锁的线程被挂起,等待锁的线程必然需要一直等待下去。对于活锁或者饥饿的场景,线程失败或者挂起的时候,其他线程完全不仅能正常运行,说不定还解决了活锁和饥饿的问题,因此活锁和饥饿符合non-,但是不符合lock-free。
实现一个lock-free数据结构并不容易,好在已经有了几种常见数据结构的的lock-free实现:, list, stack, queue, map, deque,我们直接拿来使用就行了。
优化对锁的使用
有时候没有条件使用lock-free,还是得用锁,对于这种情况,还是有一些优化手段的。首先使用尽量减少临界区的大小,使用细粒度的锁,锁粒度越细,并行执行的效果越好。其次选择适合的锁,比如考虑选择读写锁。
CPU
使用CPU 机制合理规划线程和CPU的绑定关系。前面提到使用CPU 机制,将多队列网卡的中断处理分散到多个CPU上。不仅是中断处理,线程也可以绑定,绑定之后,线程只会运行在绑定的CPU上。为什么要将线程绑定到CPU上呢?绑定CPU有这样几个好处
Linux上设置CPU 很简单,可以使用命令行工具,也可以在程序内直接调用API 和
其他优化技术
使用
Linux中,程序内使用的内存地址是虚拟地址,并不是内存的物理地址。为了简化虚拟地址到物理地址的映射,虚拟地址到物理地址的映射最小单位是“Page”,默认情况下,每个页大小为4KB。CPU指令中出现的虚拟地址,为了读取内存中的数据,指令执行前要把虚拟地址转换成内存物理地址。Linux为每个进程维护了一张虚拟地址到物理地址的映射表,CPU先查表找到虚拟地址对应的物理地址,再执行指令。由于映射表维护在内存中,CPU查表就要访问内存。相对CPU的速度来说,内存其实是相当慢的,一般来说,CPU L1 Cache的访问速度在1ns左右,而一次内存访问需要60-100ns,比CPU执行一条指令要慢得多。如果每个指令都要访问内存,比如严重拖慢CPU速度,为了解决这个问题,CPU引入了TLB( ),一个高性能缓存,缓存映射表中一部分条目。转换地址时,先从TLB查找,没找到再读内存。
显然,最理想的情况是映射表能够完全缓存到TLB中,地址转换完全不需要访问内存。为了减少映射表大小,我们可以使用“”:大于4KB的内存页。默认是2MB,最大可以到1GB。
避免动态分配内存
内存分配是个复杂且耗时的操作,涉及空闲内存管理、分配策略的权衡(分配效率,碎片),尤其是在并发环境中,还要保证内存分配的线程安全。如果内存分配成为了应用瓶颈,可以尝试一些优化策略。比如内存复用i:不要重复分配内存,而是复用已经分配过的内存,在C++/Java里则考虑复用已有对象,这个技巧在Java里尤其重要,不仅能降低对象创建的开销,还避免了大量创建对象导致的GC开销。另外一个技巧是预先分配内存,实际上相当于在应用内实现了一套简单的内存管理,比如的Slab。
Zero Copy
对于一个Web服务器来说,响应一个静态文件请求需要先将文件从磁盘读取到内存中,再发送到客户端。如果自信分析这个过程,会发现数据首先从磁盘读取到内核的页缓冲区,再从页缓冲区复制到Web服务器缓冲区,接着从Web服务器缓冲区发送到TCP发送缓冲区,最后经网卡发送出去。这个过程中,数据先从内核复制到进程内,再从进程内回到内核,这两次复制完全是多余的。Zero Copy就是类似情况的优化方案,数据直接在内核中完成处理,不需要额外的复制。
Linux中提供了几种相关的技术,包括,,,Web服务器中经常使用优化性能。
最后
千万牢记:不要过早优化。
优化之前,先考虑两个问题:
现在的性能是否已经满足需求了如果真的要优化,是不是已经定位了瓶颈
在回答清楚这两个问题之前,不要盲目动手。
CPU 线程 一个 使用 文件 连接
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
-
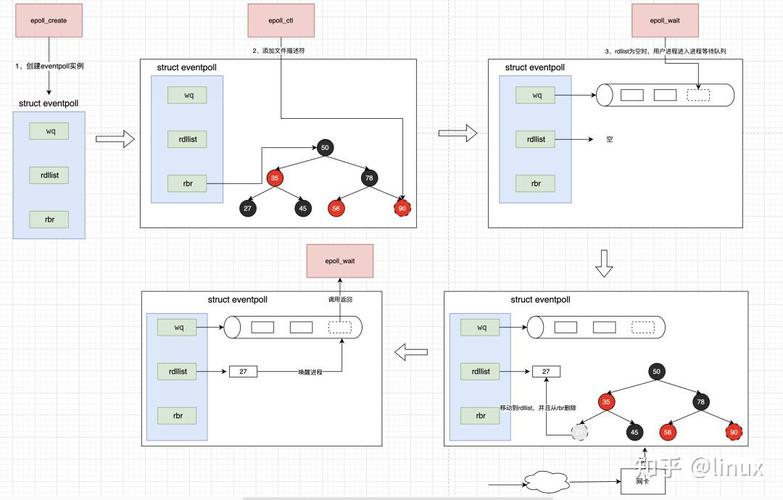
epoll vs select:高并发下谁更胜一筹?
-

找魔兽世界替代品?这10款免费单机MMO值得一试
-

魔兽玩家别急!三款免费单机游戏,和魔兽一样好玩
-
零基础学Python?这6个免费网站比女神讲师视频教程还实用
-
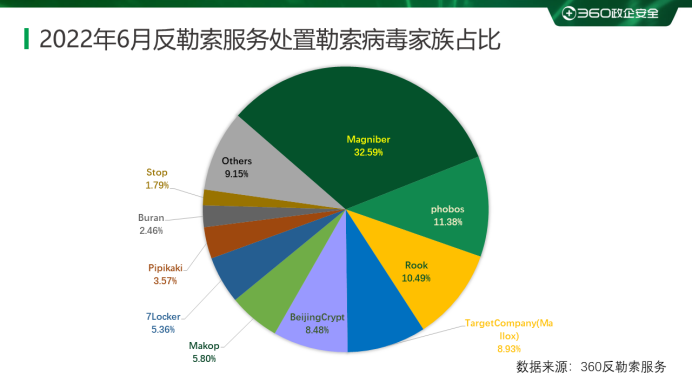
新型勒索病毒蔓延,360反勒索服务为企业和个人数据安全护航
-
不花钱的魔兽世界平替?推荐几款类似的免费单机游戏
-

阴阳鬼探txt全集下载,阴阳五行学说与鬼怪故事完美融合
-

平安金融中心 深圳:金博会上的保险黑科技,为AI时代实体经济护航
-

360查杀提示木马?教你分辨哪些是系统正常文件
-

阴阳鬼探txt全集下载|阴阳哲学与小说资源一网打尽
-

平安金融中心深圳租赁电话 18610003768 王经理
-

阴阳鬼探txt全集下载:阴阳思想与天地之道的通俗解读