最近在处理一个高并发的服务时,又碰到了I/O多路复用相关的问题。说实话,我刚接触Linux网络编程那会儿,看到、poll、epoll这些概念,脑子里就像一团浆糊。什么叫"多路复用"?为啥要"复用"?今天就来聊聊这个话题,争取把它说明白。...
epoll线程池实战:高并发WebSocket服务如何避免线程爆炸
最近在处理一个高并发的服务时,又碰到了I/O多路复用相关的问题。说实话,我刚接触Linux网络编程那会儿,看到、poll、epoll这些概念,脑子里就像一团浆糊。什么叫"多路复用"?为啥要"复用"?今天就来聊聊这个话题,争取把它说明白。
从一个真实场景说起
前段时间,我们客户的出了点问题。这个系统需要同时处理几千个客户的连接,每个客户可能随时发消息,也可能很长时间不说话。最开始的实现很简单粗暴——给每个连接分配一个线程。
结果可想而知,服务器直接撑不住了。几千个线程在那儿空转,CPU占用率飙升,内存也吃紧。这时候我才真正理解了I/O多路复用的价值。
什么是I/O多路复用
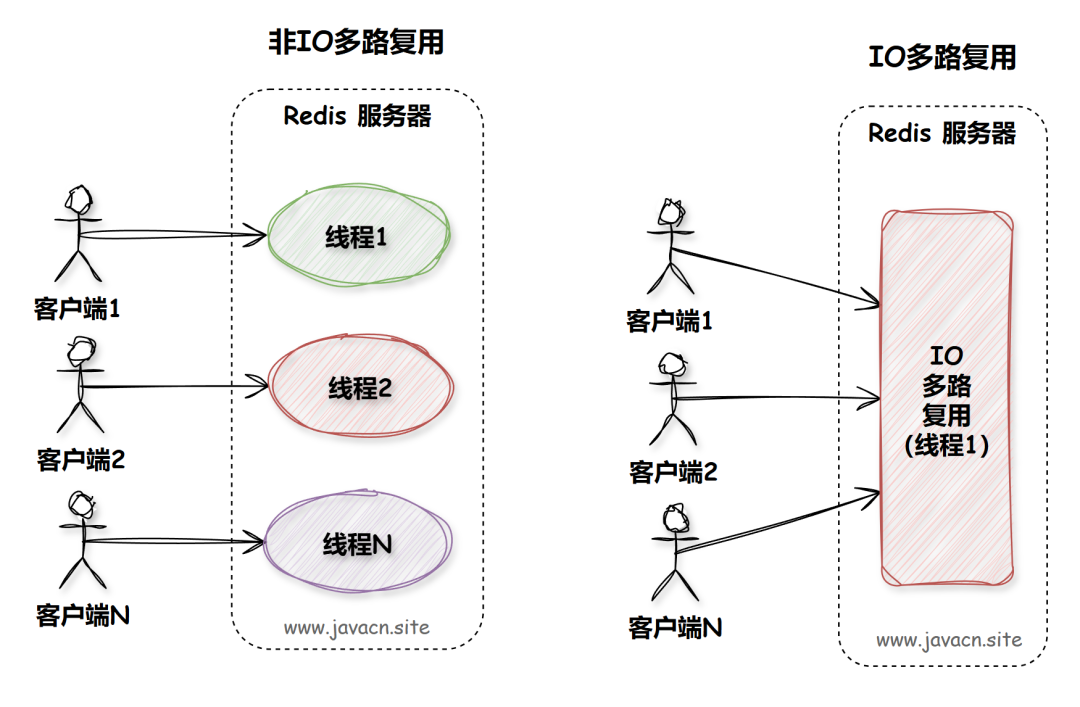
简单来说,I/O多路复用就是用一个线程监控多个文件描述符(连接),看看哪个有数据可读或可写,然后再去处理。就像一个服务员同时照看多桌客人,谁举手了就去服务谁,而不是每桌配一个服务员。
传统的阻塞I/O是这样的:
// 这段代码会一直等待,直到有数据来
int n = recv(socket_fd, buffer, 1024, 0);如果没数据,线程就在那儿傻等着,啥也干不了。要是有1000个连接,难道要开1000个线程去等?显然不现实。
I/O多路复用的思路是:既然要等,那就让一个线程同时等多个,谁有动静了就处理谁。这就是"复用"的含义——复用一个线程来处理多个I/O。
:最古老的方案
是最早的I/O多路复用方案,用起来是这样的:
fd_set readfds;
FD_ZERO(&readfds);
FD_SET(socket1, &readfds);
FD_SET(socket2, &readfds);
FD_SET(socket3, &readfds);
// 等待这些socket中有可读的
select(maxfd + 1, &readfds, NULL, NULL, NULL);
// 检查哪个socket可读
if (FD_ISSET(socket1, &readfds)) {
// 处理socket1的数据
}的问题在于:
我曾经用写过一个小型聊天服务器,几百个连接就开始卡了。每次返回,都要循环检查所有的,效率低得让人抓狂。
poll:的小改进
poll解决了的文件描述符数量限制问题:
struct pollfd fds[1000];
fds[0].fd = socket1;
fds[0].events = POLLIN;
fds[1].fd = socket2;
fds[1].events = POLLIN;
int ret = poll(fds, 2, -1);但poll的本质问题没解决——还是要遍历所有的文件描述符。想象一下,你监控了10000个连接,但只有10个有数据,你还是得检查所有10000个。这效率...
epoll:Linux的杀手锏
epoll才是真正的游戏规则改变者。它解决了和poll的核心问题:
int epfd = epoll_create(1);
struct epoll_event ev;
ev.events = EPOLLIN;
ev.data.fd = socket1;
epoll_ctl(epfd, EPOLL_CTL_ADD, socket1, &ev);
struct epoll_event events[10];
int nfds = epoll_wait(epfd, events, 10, -1);
// 只需要处理有事件的fd
for (int i = 0; i < nfds; i++) {
handle_event(events[i].data.fd);
}epoll的优势在于:
推荐客户用epoll重写了那个客服系统,同样的硬件,轻松支撑上万连接。CPU使用率从80%降到了20%,终于露出了笑容。
实战中的坑
说说我在实际使用中踩过的坑吧。
水平触发 vs 边缘触发
epoll有两种触发模式。水平触发(LT)是默认的,只要有数据可读,每次都会返回这个fd。边缘触发(ET)只在状态变化时通知一次。
我第一次用ET模式时,经常丢数据。原因是ET模式下,必须一次性把数据读完:
// ET模式下的正确读法
while (1) {
int n = recv(fd, buf, sizeof(buf), 0);
if (n <= 0) {
if (errno == EAGAIN) {
// 数据读完了
break;
}
// 真的出错了
handle_error();
}
// 处理数据
}惊群问题
多个进程监听同一个端口时,一个连接到来,所有进程都会被唤醒,但只有一个能成功。这就是"惊群"。
解决方案是使用:
int opt = 1;
setsockopt(listenfd, SOL_SOCKET, SO_REUSEPORT, &opt, sizeof(opt));或者用nginx的做法——让进程监听,进程通过锁来竞争。
实际应用Redis的单线程模型
Redis虽然是单线程,但能支撑10万+的QPS,靠的就是epoll。它的事件循环大概是这样:
while (1) {
// 等待事件
numevents = epoll_wait(epfd, events, eventsize, timeout);
for (j = 0; j < numevents; j++) {
if (是新连接) {
accept_handler();
} else if (是客户端请求) {
read_handler();
process_command();
write_handler();
}
}
}Nginx的高性能秘密
Nginx能够处理百万级并发,也是因为用好了epoll。它的进程就是一个事件循环,不断地:
1. 等待事件2. 处理连接请求3. 处理读写事件4. 继续等待
没有线程切换的开销,CPU缓存友好,性能自然高。
写在最后
I/O多路复用看起来很复杂,但核心思想很简单——用一个线程高效地管理多个I/O。从到poll再到epoll,是一个不断优化的过程。
在实际工作中,除非你在写底层网络库,否则很少直接用这些API。但理解它们的原理,对于理解和优化高并发系统非常重要。下次当你的服务扛不住压力时,不妨想想是不是I/O模型的问题。
记得有一次面试,面试官问我:"为什么Redis是单线程却这么快?"我巴拉巴拉说了一堆,最后他说:"你就说因为用了epoll不就完了吗?"虽然这么说有点简单粗暴,但确实是核心原因之一。
epoll 一个 线程 处理 数据 连接
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战