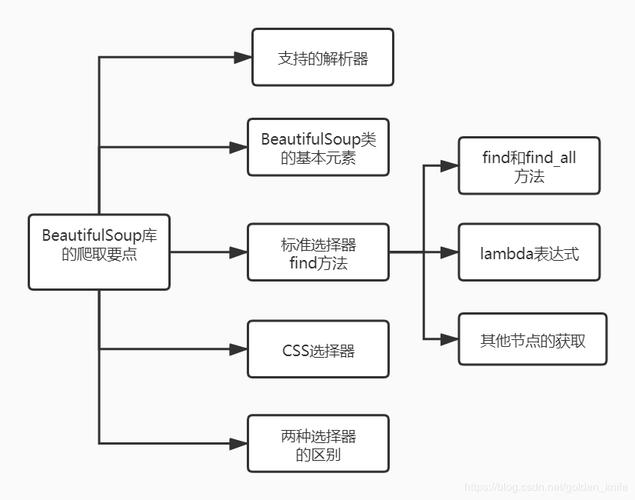
目录 一、模块简介 二、方法利用 1、引入模块 2、几个简单的浏览结构化数据的方法 三、具体利用 1、获取拥有指定属性的标签 2、获取标签的属性值 3、获取标签中的内容 4、
目录三、具体利用四、输出一、模块简介
Soup 是一个可以从H...
python爬虫beautifulsoup怎么用?标签属性内容提取教程
目录 一、模块简介 二、方法利用 1、引入模块 2、几个简单的浏览结构化数据的方法 三、具体利用 1、获取拥有指定属性的标签 2、获取标签的属性值 3、获取标签中的内容 4、
目录三、具体利用四、输出一、模块简介
Soup 是一个可以从HTML或XML文件中提取数据的库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. Soup会帮你节省数小时甚至数天的工作时间.
二、方法利用1、引入模块
# 引入 html_doc = """The Dormouse's story The Dormouse's story
Once upon a time there were three little sisters; and their names were Elsie, Lacie and Tillie; and they lived at the bottom of a well.
...
""" from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc, 'html.parser')
四种解析器
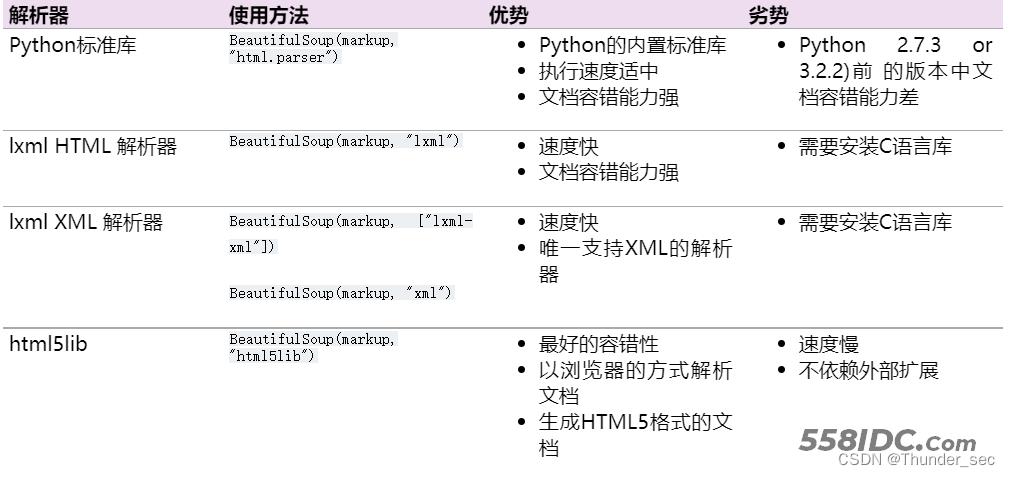
2、几个简单的浏览结构化数据的方法
#获取Tag,通俗点就是HTML中的一个个标签
#获取Tag,通俗点就是HTML中的一个个标签 soup.title # 获取整个title标签字段:The Dormouse's story soup.title.name # 获取title标签名称 :title soup.title.parent.name # 获取 title 的父级标签名称:head soup.p # 获取第一个p标签字段:The Dormouse's story
soup.p['class'] # 获取第一个p中class属性值:title soup.p.get('class') # 等价于上面 soup.a # 获取第一个a标签字段 soup.find_all('a') # 获取所有a标签字段 soup.find(id="link3") # 获取属性id值为link3的字段 soup.a['class'] = "newClass" # 可以对这些属性和内容等等进行修改 del bs.a['class'] # 还可以对这个属性进行删除 soup.find('a').get('id') # 获取class值为story的a标签中id属性的值 soup.title.string # 获取title标签的值 :The Dormouse's story
三、具体利用1、获取拥有指定属性的标签
方法一:获取单个属性
soup.find_all('div',id="even") # 获取所有id=even属性的div标签
soup.find_all('div',attrs={'id':"even"}) # 效果同上
方法二:
soup.find_all('div',id="even",class_="square") # 获取所有id=even并且class=square属性的div标签
soup.find_all('div',attrs={"id":"even","class":"square"}) # 效果同上
2、获取标签的属性值
方法一:通过下标方式提取
for link in soup.find_all('a'):
print(link['href']) //等同于 print(link.get('href'))
方法二:利用attrs参数提取
for link in soup.find_all('a'):
print(link.attrs['href'])
3、获取标签中的内容
divs = soup.find_all('div') # 获取所有的div标签
for div in divs: # 循环遍历div中的每一个div
a = div.find_all('a')[0] # 查找div标签中的第一个a标签
print(a.string) # 输出a标签中的内容
如果结果没有正确显示,可以转换为list列表
4、
去除\n换行符等其他内容
divs = soup.find_all('div')
for div in divs:
infos = list(div.stripped_strings) # 去掉空格换行等
bring(infos)
四、输出1、格式化输出()
() 方法将 Soup的文档树格式化后以编码输出,每个XML/HTML标签都独占一行
markup = 'I linked to example.com' soup = BeautifulSoup(markup) soup.prettify() # '\n \n \n \n \n...' print(soup.prettify()) # # # # # # I linked to # # example.com # # # #
2、()
如果只想得到tag中包含的文本内容,那么可以调用 () 方法,这个方法获取到tag中包含的所有文版内容包括子孙tag中的内容,并将结果作为字符串返回:
markup = '\nI linked to example.com\n' soup = BeautifulSoup(markup) soup.get_text() u'\nI linked to example.com\n' soup.i.get_text() u'example.com'
到此这篇关于 Soup模块使用教程详解的文章就介绍到这了,更多相关 Soup内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!
获取 标签 div 方法 soup.find all
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战
最近发表
-

理财故事:基金投教如何帮普通人赚到长期钱
-
电脑无法从U盘引导启动?先改BIOS再查U盘制作
-

如何做好信息安全?从骚扰电话看个人信息泄露维权
-

如何做好信息安全?5分钟搞定这5件事,保护个人数据安全
-

修改符号有哪些?教你用对modify、revise、amend、alter
-

普通人如何做好信息安全?云南网警教你防信息泄露
-

贯彻总书记指示精神,做好网络安全工作的总体目标与要点
-

学校演习变搞笑赛跑,学生跑丢方向笑翻全场
-

cmdb 外贸稳增显韧性,中国制造全球供应链优势凸显
-

学校元旦联欢搞笑新闻稿:老师们的才艺翻车现场
-

U盘装系统进不去引导?教你几招解决启动失败
-

学校搞笑新闻稿:开学典礼上校长讲段子,新生笑翻全场