精确去重,使用的哈希(Hash),它可以快速判断文本是否完全一致
对于语义去重,我们是利用语义向量()+相似度计算的方法
具体做法是把文本转成高维向量,然后计算它们的余弦相似度。
当相似度超过某个阈值(比如0.9或0.95)时,我们就判定这...
beautifulsoup3 从0到1构建RAG知识库
精确去重,使用的哈希(Hash),它可以快速判断文本是否完全一致
对于语义去重,我们是利用语义向量()+相似度计算的方法
具体做法是把文本转成高维向量,然后计算它们的余弦相似度。
当相似度超过某个阈值(比如0.9或0.95)时,我们就判定这些文本是语义重复,从而进行合并或过滤。
这种方法能有效识别“我想开户”和“怎么开账户”这类表达不同但意思相同的文本,是智能客服和RAG系统中提升知识库质量的关键。
通俗来说:哈希就像是文本的“身份证号码”,严格匹配;而语义向量是文本的“脸部识别”,看整体相似度。
比较相似度的几种方法:
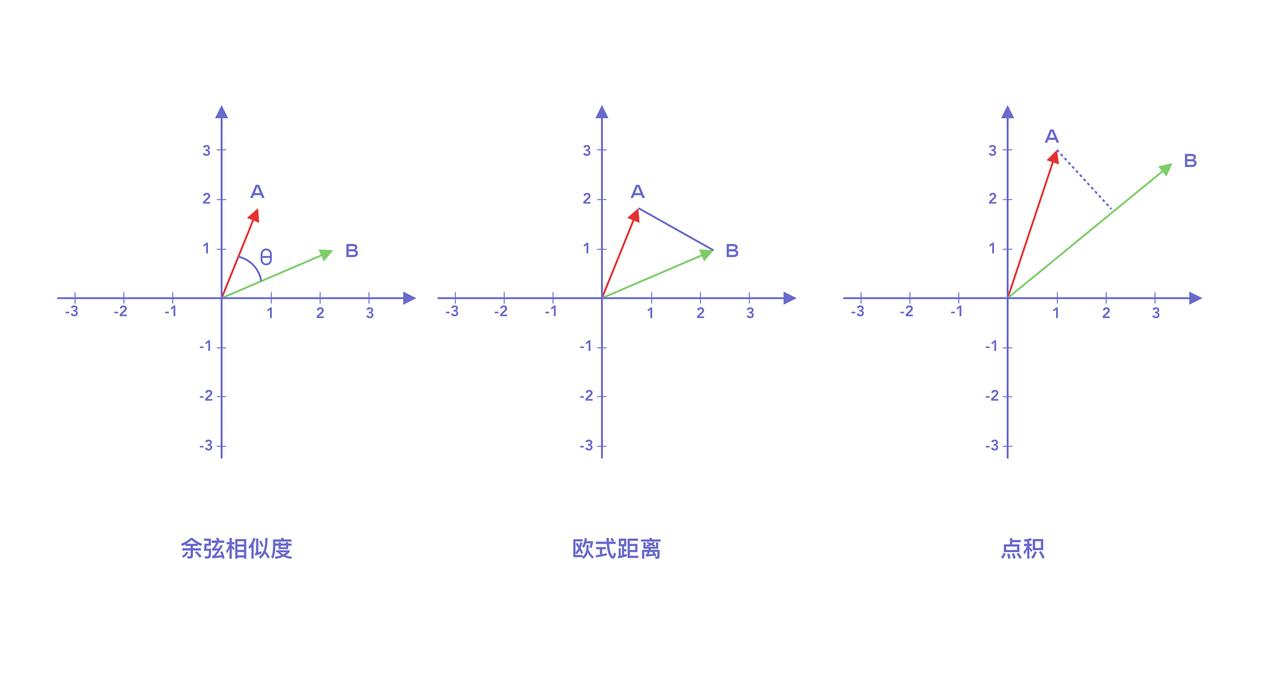
余弦相似度:含义:计算两个向量之间的夹角余弦值
数学公式:cos(θ) = A·B / (‖A‖‖B‖)特点:关注方向,不考虑向量长度
应用场景:稳定性好,语义类首选欧式距离:计算两个向量之间的“空间直线距离”数学公式:√Σ (Ai-Bi)²特点:关注绝对位置差值,受向量长度影响大
应用场景:几何直觉强(图像/物理空间定位类问题常用)点积:向量内积,考虑方向和长度数学公式:A·B = ΣAi*Bi特点:值大代表方向一致且“强”,值小代表方向偏离
应用场景:高效计算,与模型训练兼容性强。
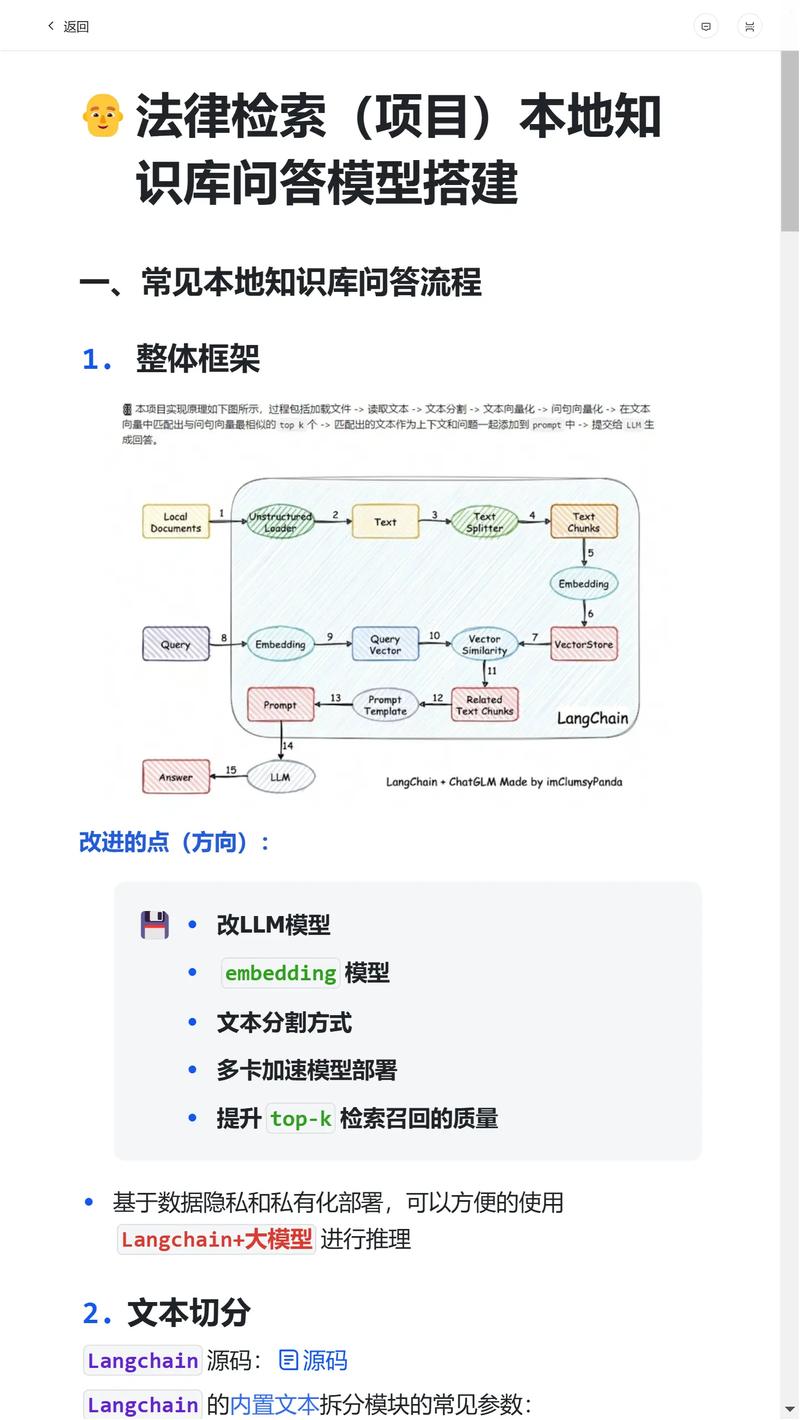
第三阶段:内容切分()
目标:构造最小可复用、可引用的知识单元。
常见做法是 基于规则 +NLP模型:
规则切分按字符数(比如 200–500 字一个 chunk);
容易踩坑的点:切分过大召回噪声多、过小上下文断裂。
关于不同的格式PDF、图片、图文混合、语音、视频类如何切分,我做一个更详细的介绍,欢迎大家继续阅读~
3.1 PDF 文件如何切分?
根据 文档逻辑结构 + 可视排版信息 + 语义完整性三个维度进行切分。
整个流程可以分为以下几步:
1)文档解析
使用 解析文本和排版结构(如字体大小、缩进、标题层级);
如果是扫描件PDF,则通过 OCR(如 + 表格检测)还原内容。
2)结构识别
通过正则表达式或标题风格识别“章节标题”、“条款编号”(如 第 X 条、1.2.3)作为一级切分点;
根据空行、缩进、符号判断自然段落边界。
3)分块切分()
按照“一级标题 + 段落”组合成一个chunk,保持上下文完整;
每个chunk控制在300-500 ,超长内容采用滑窗 + ;
若chunk包含表格,则先展开表格结构再切分。
4)元数据补全
为每个chunk添加文档标题、页码、版本、发布日期等元信息,方便后续追溯与响应定位;
切分质量验证
随机抽样chunk进行 相似度热图分析,检查语义跳跃或中断问题;
还会做人工 spot-check,确保每个chunk语义通顺、结构清晰。
3.2 图片类如何切分?
对于图片类数据,我们通常分为两步:先进行内容识别,再进行语义切分。
1)图片预处理
对图片做去噪、去水印、裁剪等基础图像处理,保证后续识别质量;
对文档类图片使用图像增强技术提高OCR准确率。
2)OCR 文字识别
使用高性能OCR工具识别图片中的文字和表格;
同时提取文字位置、字体大小、布局信息,辅助后续切分。
3)图像分块与切分
根据OCR识别的文字位置,结合图像的空间布局,做逻辑区域划分;
对于图表类图片,我们会先做图表结构识别(图例、坐标轴、图形元素),再拆分成对应的文字描述+结构块。
4)语义级别切分
在文本提取后,按照自然语言的断句和业务逻辑进行语义切分,保证内容的完整性和上下文连续;
对图表、合同页等内容,会做额外的语义补充说明,方便向量召回。
5)元信息补充
每个切块会标记图片来源、页码、截图时间等,便于回溯和查询。
我们确保图片类数据不仅能被“看懂”,而且可以高效地参与到知识检索与智能问答中。
3.3 音频类如何切分?
这里主要用到ASR
ASR(自动语音识别)是将语音信号转化为对应文本的技术,是语音类数据接入自然语言处理系统的第一步。
在券商的智能客服项目中,ASR负责:
为后续语义分析和RAG提供文本基础。
识别文本成为后续语义切分、知识检索的关键数据来源。
3.4 文图如何切分?
文图混合数据(比如图文并茂的公告、报告、投研资料)非常常见。
文图混合数据的切分,核心是图文切分的关键是确保文图是对的上的,把“视觉信息”和“文本信息”统一到语义层面,保证切块既有完整文字内容,也能体现图片或图表的语义关联。
1)图文内容提取
使用 OCR 工具(如 、腾讯OCR)提取图片中的文字和表格信息;
对文本块做自然语言处理,做断句和语义分析。
2)版面结构分析
3)语义融合切分
结合图像内容分类(图表、照片、流程图等)和文本主题,按业务逻辑将图文组合成语义完整的切块;
对图表类图片做结构化描述,融合成文字块,确保图文信息同步传递。
4)多模态向量生成
生成文本向量和图像向量(使用CLIP、BLIP等多模态模型),辅助判断切块的语义边界,避免切分断裂;
5)元信息补全
每个切块标注来源页码、图文位置、版本信息,方便后续追溯和精确响应。
第四阶段:向量化
向量化:将每个知识片段转化为向量表示(比如Open AI的 接口)
借助模型,将切分好的片段转化成向量(数字组成的)。
市面上主流的文本模型大致可以分为三类:
1)通用(适用于多语种 / 多场景):
2)中文专用(适用于中文客服 / 文档场景):
3)多模态/多语言(适用于网页混排、OCR文档等):
在我们券商RAG项目中,我们做过模型的A/B对比,最后选择了:
中文主向项目使用 bge-base-zh(百度开源),因为它在金融语义聚类和FAQ相似度匹配上的表现优于模型,且支持本地部署,方便做私有化;
涉及英文合规文档,我们选用 text--ada-002 来构建中英文混合知识库;
部分内容我们还试验过 bge-m3,它支持“多功能向量”(一次可用于检索、聚类、排序),效果也不错。
第五阶段:数据入库
完成向量化后,知识就变成了一块块可计算的“向量碎片”,但要让它真正发挥作用,还需要进入一个 高效、可控、可扩展的数据库——这就是数据入库的环节。
在 RAG 项目中,数据入库不仅仅是“存进去”,而是要保证 检索准确、更新及时、调用高效、安全合规。
5.1 选择合适的存储方式
常见的两类存储方案:
1)向量数据库(如 、Faiss、、):
适合客服问答等“召回-排序-生成”的场景
2)关系型/文档型数据库(如 MySQL、、):
在金融业务中,通常与向量数据库 混合使用( )
5.2 知识元数据管理
除了向量本身,还要存储丰富的 元数据,方便检索时做条件过滤。 常见元数据包括:
5.3 数据更新与增量入库
知识库是“活”的,不断有新公告、新政策、新业务上线。
因此,入库需要支持:
在金融场景下,这点尤为重要:比如 印花税下调、交易规则修改、公司行动变更,知识库必须在当天完成更新,才能避免客服答错。
5.4 安全与合规
在券商业务里,数据入库还必须满足金融行业的合规要求:
数据入库的目标不是“存得下”,而是要做到:
只有把知识存得“对、快、稳”,后续的检索增强(RAG)才能真正发挥价值,让智能客服既 答得准,又答得放心。
还想补充一下,知识库不是一次性工程,而是一条“持续迭代的生命线”。
随着市场规则更新、业务流程调整,我们需要不断优化数据源、切分方式和向量检索策略,让 AI 始终与最新业务保持同步。
如果说大模型是“通用大脑”,那么 RAG 就像是给大模型装了一个知识外挂。原本只能靠“记忆”回答问题的语言模型,现在可以在回答前“查资料”,不仅提升了准确率,也让生成内容更加贴合用户的真实需求。
未来,谁能把知识库建设好,谁就能率先跑通智能化的应用闭环。
切分 语义 向量 文本 数据 图片
热门文章
-
杭州文海实验多名学生流鼻血,官方连夜成立联合工作组彻查工厂排放
-

万茜颜值进阶史:从青涩到“清冷系天花板”的蜕变之路
-

杨少华遗体告别仪式:亲友送别,赵本山送花圈,杨威杨议忙后事
-

长江商学院自创办第一天起 始终以为中国和世界培养一批具有全球视野
-

深圳南山区“美澳口腔”诊所“跑路”风波:数百患者维权,交款种牙却陷入困境
-

“超级工程”渐行渐近,重庆破局,宜昌“躺赢”?
-

国务院总理李强在天津出席2025年夏季达沃斯论坛工商界代表座谈会
-

首份2025年中报周二亮相,12家公司净利润预增超10倍,华银电力暂居榜首
-
电脑恢复出厂设置步骤详解:备份数据及各操作要点
-

十三岁的星辰:云南女孩侯静怡短暂而明亮的一生
-

广州英华思力足球俱乐部翻译徐进遭日籍教练霸凌猝死,家属讨公道
-

巨子生物“变卦”背后:胶原蛋白检测风波与医美巨头商战